In the modern healthcare landscape, the ability to assess and predict patient risks is paramount. Healthcare risk stratification—the process of categorizing patients based on their likelihood of experiencing specific outcomes—enables personalized interventions, optimized resource allocation, and improved health outcomes. While traditional methods like simple risk scores have been widely used, advanced statistical techniques are increasingly being adopted to provide more accurate and granular insights.
Advanced statistical techniques, including machine learning, survival analysis, and natural language processing, offer healthcare providers the ability to assess risk more accurately, predict adverse events before they occur, and tailor interventions to individual patient needs. These techniques leverage vast amounts of data from electronic health records (EHRs), wearables, and other sources to provide real-time insights into patient health, transforming how healthcare risks are managed
What is Healthcare Risk Stratification?
Risk stratification in healthcare refers to the process of categorizing patients into different risk levels based on their likelihood of developing certain health conditions or experiencing specific health outcomes. This enables healthcare providers to:
- Identify high-risk patients who need immediate intervention.
- Personalize treatment plans for patients based on their risk profiles.
- Optimize the allocation of healthcare resources, reducing costs and improving efficiency.
For instance, by identifying which patients are at high risk of hospital readmission, hospitals can take preventive measures to reduce avoidable admissions. This approach is central to value-based care models, where healthcare providers are incentivized to improve patient outcomes while reducing costs.
Key Statistical Techniques for Healthcare Risk Stratification
To achieve effective risk stratification, healthcare providers rely on advanced statistical techniques. Below are some of the most important methods used in this process.
Logistic Regression
Logistic regression is a foundational technique for binary classification problems. It estimates the probability of a particular outcome based on one or more input variables, making it a staple in healthcare analytics.How it works:
1. Uses patient demographic, clinical, and historical data as input variables.
2. The model applies a logistic function to map the inputs to a probability range between 0 and 1.
3. A threshold (e.g., 0.5) determines the predicted class: “event” or “no event.”Example:
1. Predicting hospital readmissions within 30 days of discharge for patients with chronic conditions.
2. Identifying patients at high risk for adverse drug reactions.Why it’s effective:
1. Simple and interpretable, allowing healthcare providers to understand the contribution of each factor
2. Performs well with small to moderately sized datasets
3. Suitable for binary outcomes (e.g., “at risk” vs. “not at risk”)Decision Trees and Random Forests
Decision trees are intuitive models that split data into branches based on decision rules, while random forests enhance their robustness by combining multiple trees in an ensemble.
How it works:
1. Decision trees recursively partition data into subsets based on feature thresholds.
2. Random forests create multiple decision trees with random subsets of data and features, combining their predictions for improved accuracy.Example:
1. Predicting chronic disease progression, such as diabetes advancing to cardiovascular disease.
2. Identifying factors contributing to post-surgical complicationsWhy it’s effective:
1. Can handle complex, non-linear relationships between variables
2. Robust to outliers and missing data (especially random forests)
3. Suitable for both classification and regression problemsClustering (K-means, Hierarchical Clustering)
Clustering is an unsupervised learning technique used to group patients with similar characteristics or patterns without predefined labels.
How it works:
1. K-means divides the data into a pre-specified number of clusters by minimizing within-cluster variance.
2. Hierarchical clustering builds a tree-like structure to represent nested groupings.
Example:
1. Segmenting patients with chronic illnesses to tailor interventions.
2. Grouping high-cost patients for resource allocation in population health management.Why it’s effective:
1. Helps uncover hidden patterns in unstructured or semi-structured data
2. Supports personalized medicine and precision care by grouping patients with similar needsSurvival Analysis (Cox Proportional Hazards Model, Kaplan-Meier Estimation)
Survival analysis is a statistical approach designed to model time-to-event data, often used in medical research and risk prediction.
How it works:
1. The Cox proportional hazards model assesses the relationship between survival time and covariates.
2. Kaplan-Meier curves visualize survival probabilities over time.Example:
1. Estimating the likelihood of disease recurrence after treatment.
2. Predicting time to hospital readmission for patients with chronic conditions.Why it’s effective:
1. Effective for censored data, where the event of interest may not occur during the study period
2. Helps identify risk factors that influence survival timesAdvanced Machine Learning Techniques (Neural Networks, Support Vector Machines, Gradient Boosting)
Machine learning (ML) models, such as Neural Networks, Support Vector Machines (SVMs), and Gradient Boosting Machines (GBMs), offer powerful tools for uncovering complex patterns in healthcare data.
How it works:
1. Neural Networks: Mimic human brain function through layers of interconnected neurons, excelling in feature extraction from large datasets.
2. SVMs: Find hyperplanes to separate data into classes, often used for high-dimensional datasets.
3. Gradient Boosting (e.g., XGBoost, LightGBM): Sequentially builds models to correct errors from previous iterations, offering state-of-the-art performance in structured data.Example:
1. Predicting cardiovascular events using patient data from wearable devices.
2. Assessing cancer recurrence risk based on genomic and imaging data.Why it’s effective:
1. Capable of handling large, high-dimensional datasets with numerous features.
2. Flexible in capturing complex, non-linear relationships that traditional models may miss.
3. ML algorithms can incorporate diverse data sources, including imaging, genomic, and sensor data.

Applications of Risk Stratification in Healthcare
Advanced statistical techniques are being applied in numerous areas of healthcare to improve patient outcomes, reduce costs, and streamline operations. Here are a few key applications:
Predicting Hospital Readmissions
Hospitals use logistic regression and survival analysis to identify which patients are most at risk of being readmitted. This allows them to provide tailored discharge plans and follow-up care.Managing Chronic Disease
For chronic diseases like diabetes, heart disease, and hypertension, clustering and decision trees help segment patients based on disease progression. Healthcare providers can then offer targeted interventions to reduce disease burden.Personalized Treatment Plans
Machine learning algorithms like neural networks analyze patient data to develop individualized care pathways. For example, patients with similar risk profiles may receive customized health coaching or wellness plans.Resource Allocation and Cost Reduction
Healthcare systems use predictive models to identify patients who are at higher risk of hospitalization or emergency visits. This enables proactive care management, reducing the cost of emergency interventions.Population Health Management
Risk stratification at the population level identifies groups of people who are at higher risk of specific diseases, such as cardiovascular disease. Public health organizations can then create targeted public health initiatives.
A Case Study from JAMIA Open: Harnessing Statistical Techniques for Hospital Outcome Prediction
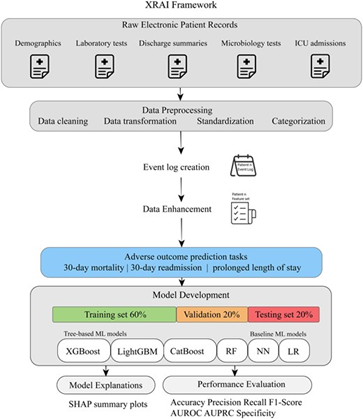
A recent study published in JAMIA Open offers a compelling example of how statistical and machine learning techniques can be harnessed to predict adverse hospital outcomes. This study demonstrates the potential of electronic patient records (EPRs) to forecast risks such as 30-day mortality, hospital readmission, and prolonged length of stay (PLOS). Here’s a detailed look at the study’s approach, statistical methodologies, and findings.
Study Objective:
The study aimed to investigate the predictive capabilities of historical patient records in identifying adverse outcomes, including mortality, hospital readmission, and prolonged length of stay (PLOS). The objective was to develop a framework that combines advanced machine learning (ML) techniques with interpretable, statistically grounded insights to improve early risk stratification in hospital settings.
Methods:
The study utilized a de-identified dataset from a tertiary care university hospital, focusing on patients suspected of bloodstream infections. The researchers engineered features from patients’ medical histories, including age, temporal patterns, laboratory test results, and diagnostic and procedural codes. A novel eXplainable Artificial Intelligence (XAI) framework was designed, combining both tree-based machine learning models, such as eXtreme Gradient Boosting (XGBoost) and traditional ML algorithms (e.g., Logistic Regression) to assess predictive performance.